Pourquoi LoRA se casse en production et comment RS-LoRA sauve le fine-tuning des modèles
LoRA fonctionne bien quand les modèles doivent changer de ton, de format ou de personnalité, mais fonctionne moins bien lorsqu'il faut ajouter de nouveaux…
Traité par IA depuis MarkTechPost ; édité par Hamidun News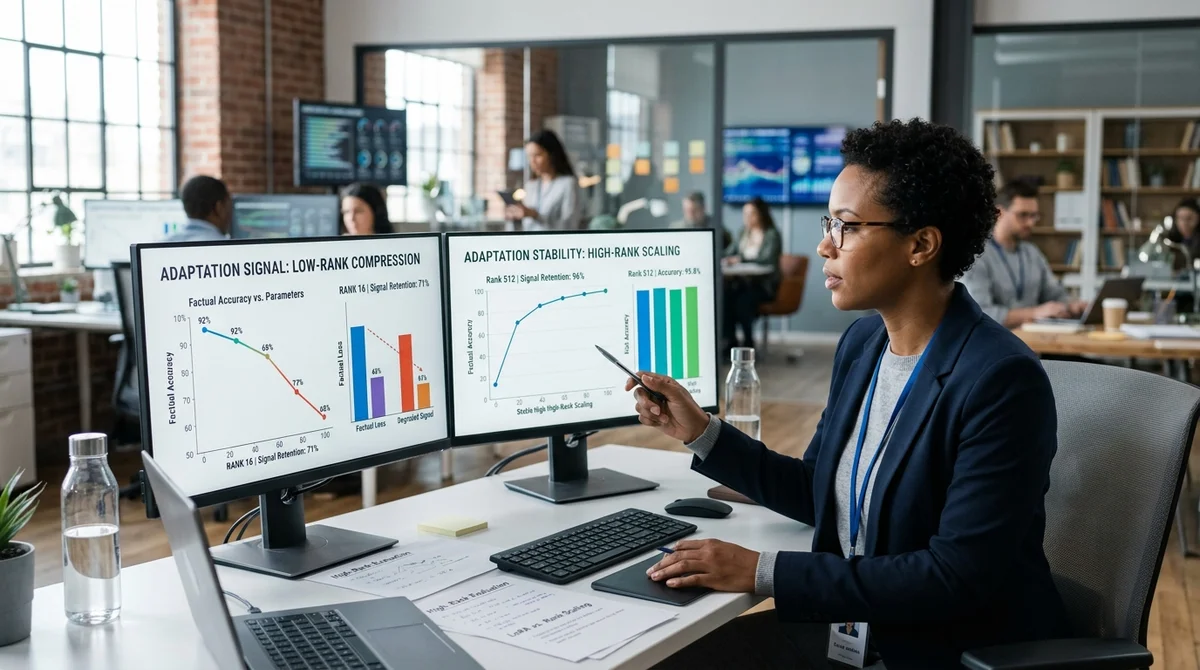
LoRA est depuis longtemps devenu le standard pour le fine-tuning bon marché de grands modèles, mais en production, il repose sur une hypothèse cachée : que toutes les mises à jour de poids sont structurées de la même manière. En pratique, ce n'est pas le cas — les changements responsables du style sont effectivement compacts, tandis que les mises à jour qui ajoutent de nouveaux faits et une expertise de domaine sont distribuées sur de nombreuses dimensions, et c'est précisément là que le LoRA standard commence à perdre des données. La popularité de LoRA est compréhensible : la méthode permet d'affiner un modèle sans recalculer tous les paramètres, en utilisant de petites matrices de faible rang.
Cela fonctionne très bien quand vous devez changer le ton, le format de réponse, le personnage ou les habitudes de parole de l'assistant. L'article le démontre sur une matrice de poids simplifiée de 64×64 : dans les mises à jour de style, plusieurs valeurs singulières dominent fortement, donc une approximation de rang 4 ou 8 préserve le signal presque complètement. Dans leur simulation, même au rang 4, ils parviennent à couvrir plus de 99% de la variation utile.
Par conséquent, un chatbot apprend facilement un nouveau style de communication, un modèle de réponse ou une manière souhaitée sans réentraînement lourd de l'ensemble du modèle. Les problèmes commencent quand vous devez enseigner non la forme, mais le contenu : des faits médicaux, des catalogues de produits, des réglementations internes, des statistiques ou des règles de l'industrie. Ces mises à jour se comportent comme haut rang : l'information est dispersée sur de nombreuses directions plutôt que concentrée dans quelques composantes dominantes.
Dans l'expérience de l'article, le rang 8 ne retient qu'environ 28% du signal réel. D'où l'effet familier en production : le modèle semble confiant, utilise la terminologie correcte et une structure de réponse appropriée, mais confond les chiffres, omet des détails ou fournit des conclusions incomplètes. Pour les assistants d'entreprise, l'analytique, l'assistance et les scénarios dépendant des connaissances, ce n'est plus une simple erreur cosmétique mais un risque de qualité.
La différence clé est clairement visible dans le spectre des valeurs singulières. Les tâches de style ont un coude évident : après quelques composantes, les dimensions supplémentaires n'apportent presque rien. Avec les faits — une longue traîne, où chaque composante successive ajoute une partie de la connaissance utile.
Quand LoRA coupe brusquement une telle mise à jour à faible rang, elle coupe précisément cette traîne. Extérieurement, le système peut toujours sembler amélioré car le format, le ton et la structure sont devenus plus nets, mais la précision réelle augmente notablement moins qu'il n'y paraît dans les tests de surface. Cela explique pourquoi les belles réponses de démonstration et le bon style ne garantissent pas un comportement fiable sur les données de production.
La réaction logique de l'ingénieur est simplement d'augmenter le rang. Mais le LoRA standard a un deuxième problème caché : l'échelle alpha/r. Plus le rang est élevé, plus le coefficient est comprimé et plus le signal d'entraînement s'affaiblit.
Dans l'exemple avec alpha = 16, l'échelle tombe de 16 au rang 1 à 0,25 au rang 64. Vous obtenez un paradoxe : vous ajoutez de la capacité au modèle pour qu'il puisse représenter une mise à jour plus complexe, mais simultanément vous réduisez l'impact réel de cette mise à jour sur les poids. L'optimiseur doit compenser par des étapes plus agressives, ce qui fait que l'entraînement converge mal ou devient instable.
C'est pourquoi le conseil d'augmenter le rang en production ne résout souvent pas le problème et masque parfois simplement le problème. RS-LoRA offre une correction minimale mais importante : utiliser alpha/√r au lieu de alpha/r. Formellement, c'est presque juste remplacer un symbole, mais en pratique, l'effet est significatif.
Au rang 64, l'échelle reste 2,0 au lieu de 0,25, donc l'adaptation de haut rang préserve une magnitude significative et ne tue pas le signal. L'article le démontre sans boucles d'entraînement lourdes ni frameworks — seulement via NumPy, SVD et comparaison des erreurs de reconstruction. Pour cette raison, l'argument semble particulièrement clair : les tâches de style de faible rang sont toujours bien résolues par le LoRA standard, tandis que les tâches d'ajout de connaissances nécessitent soit RS-LoRA, soit une stratégie d'adaptation fondamentalement différente dès le départ.
La conclusion pour les équipes déploiement des LLM fine-tunés en production est assez directe : la configuration du adaptateur doit être choisie non seulement par budget et vitesse, mais aussi par le type de mise à jour. Si vous changez le ton, le personnage ou le format de réponse, le LoRA de faible rang standard est généralement suffisant. Si vous déployez de nouveaux faits, des données de référence, des règles ou une expertise de domaine, un faible rang peut créer l'illusion d'un entraînement réussi tout en perdant silencieusement une partie substantielle de l'information.
Dans ces cas, RS-LoRA ne semble pas une optimisation subtile, mais une exigence pour la fiabilité du modèle en exploitation réelle.
Vous voulez cesser de lire sur l'IA et commencer à l'utiliser?
AI News est un fil d'actualité IA. Hamidun Academy vous apprend à utiliser l'IA dans votre travail.