Anthropic e Claude Opus 4.7: o consumo real de tokens foi superior ao anunciado
O tokenizador do Claude Opus 4.7 mostrou-se muito mais voraz do que a Anthropic havia anunciado. Em dois testes práticos, o aumento foi de 1.47x em…
Processado por IA de Habr AI; editado por Hamidun News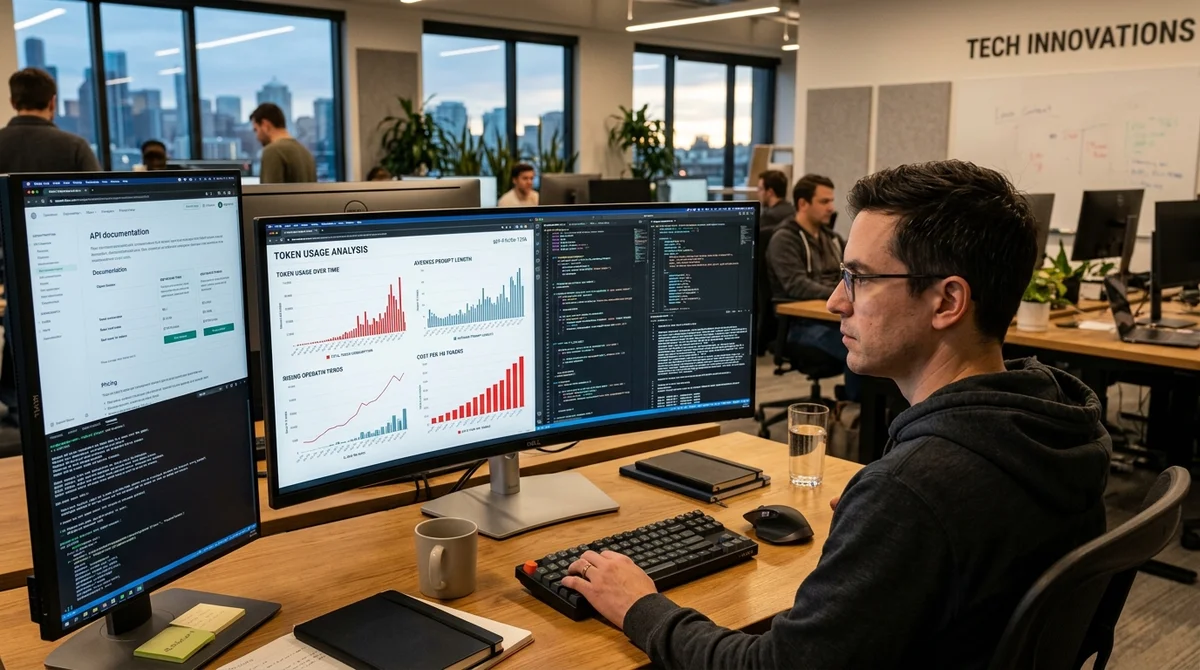
O novo tokenizador do Claude Opus 4.7 pode aumentar significativamente o custo de uso do modelo: em testes reais, o consumo ficou mais próximo de 45–47%, e não dos 0–35% afirmados no guia de migração do Anthropic. Para equipes que trabalham com prompts longos, instruções de sistema grandes e prefixos cacheáveis, essa não é uma diferença cosmética, mas um golpe direto nas quotas, velocidade e custo de cada sessão.
O motivo dessa análise foi a discrepância entre promessas e prática. Na documentação do Anthropic, consta que o novo tokenizador usa aproximadamente 1,0–1,35 vezes mais tokens em comparação com a versão do Opus 4.6.
O autor decidiu verificar isso não em exemplos abstratos, mas em materiais que realmente se assemelham à carga de trabalho real dos desenvolvedores. Na primeira medição, ele executou documentação técnica pelo tokenizador e obteve crescimento de até 1,47x. Na segunda, pegou um arquivo CLAUDE.
md real—um contexto instrucional grande—e viu quase o mesmo resultado: 1,45x. A diferença do limite superior do guia é muito grande para ser considerada ruído de medição normal. O problema não é o crescimento dos tokens em si: às vezes um tokenizador mais pesado realmente oferece benefícios em qualidade, estabilidade ou suporte a textos complexos.
A questão é que o Anthropic não muda os preços e quotas em resposta. Se o mesmo texto agora ocupa mais tokens, o usuário atinge limites de contexto mais rápido, encontra rate limit mais cedo e gasta mais orçamento por iteração. Isso é particularmente doloroso em cenários com prompts de sistema longos, conjuntos de regras, respostas de exemplo, pedaços de documentação e prefixos cacheáveis que são enviados repetidamente.
No papel a taxa é a mesma, mas a capacidade realmente útil é menor. Por isso o autor foi além de contar simplesmente e tentou entender o que exatamente o modelo recebe em troca. Com base na descrição do experimento, as vantagens afirmadas do novo tokenizador e seu comportamento em tarefas práticas foram testados.
A conclusão-chave é que nenhuma compensação milagrosa ocorreu: pelo menos nos cenários testados, o aumento no consumo foi muito notável, e o benefício não pareceu tão óbvio e sistemático. Em outras palavras, da perspectiva de alguém que paga por tokens ou vive dentro de quotas de assinatura, o trade-off parece desfavorável ao usuário. Isso não necessariamente significa que Opus 4.
7 é pior como modelo, mas significa que sua economia ficou menos confortável. Para o mercado, isso é um sinal importante. O tokenizador raramente é discutido fora de um círculo restrito de engenheiros, embora seja precisamente ele que determina quanto texto real cabe na janela de contexto e quanto cada operação custa além da API.
Uma diferença de 5–10% é frequentemente tolerável e pode se perder no contexto da variabilidade normal de requisições. Mas um salto de aproximadamente 45% não é mais uma miudeza técnica, mas um fator que afeta arquitetura de agentes, comprimento de instruções de sistema, estratégia de caching e até a unit economics de um produto. Se uma equipe tem um pipeline onde o mesmo prefixo grande participa de centenas de chamadas, os tokens extras começam a consumir dinheiro e throughput muito rapidamente.
A conclusão prática é simples: a migração para Claude Opus 4.7 deve ser avaliada não pela formulação de marketing no guia de migração, mas pelos seus próprios corpora de texto real. Vale a pena executar separadamente prompts de sistema, arquivos de instruções, documentação, templates de tarefas de agente, e tudo que frequentemente entra em contexto.
Se as medições mostrarem crescimento próximo a 1,45x, a equipe pode ter que aparar prompts, mover parte da lógica para fora do contexto, reconsiderar caching, ou até mesmo adiar a migração até benefícios mais claros emergirem. A lição principal aqui é que a qualidade do modelo não pode ser avaliada apenas por demos e benchmarks: às vezes o que importa mais não é a inteligência da resposta, mas o custo de cada token extra.
Quer parar de ler sobre IA e começar a usar?
AI News é um feed curado de notícias de IA. A Hamidun Academy ensina você a usar IA no trabalho.