L'LLM a Imaginé une Ligne d'Écoute: Pourquoi les Prompts Ne Préviennent Pas les Hallucinations
Un bot LLM a détecté des signes de maltraitance émotionnelle dans les messages d'une utilisatrice et lui a suggéré d'appeler une 'ligne d'écoute'. Le numéro…
Traité par IA depuis Habr AI ; édité par Hamidun News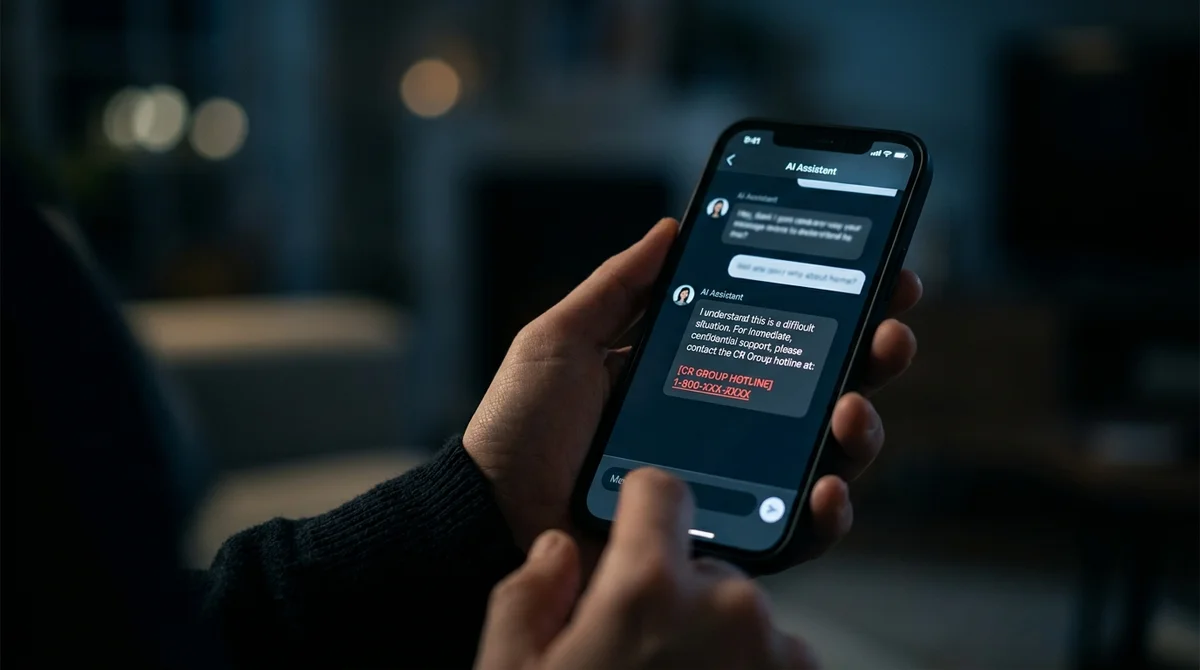
Le bot LLM a détecté des signaux alarmants dans une conversation et a recommandé d'appeler une ligne d'écoute. Le numéro s'est avéré être celui d'une ligne pour enfants—le modèle l'avait inventé. Le prompt contenait une interdiction explicite : « n'invente pas de données de contact ». Cela n'a pas aidé. Ce n'est pas un bug qu'on peut corriger avec des paroles magiques. C'est un problème architecturel. Le scénario est réel et préoccupant.
Une fille transmet au bot une conversation avec son petit ami. Le modèle reconnaît des schémas : pression émotionnelle, isolement, gaslighting. Il répond comme un assistant bienveillant—suggère de chercher de l'aide professionnelle et fournit un numéro spécifique. Tout semble logique sauf une chose : le numéro s'est avéré être celui d'une ligne de crise pour enfants. Le modèle a généré une séquence plausible de chiffres parce que c'est exactement ce qu'il fait le mieux—prédire ce qui semble approprié.
Le problème n'est pas la malveillance ni un prompt mal écrit. Les modèles de langage sont entraînés à prédire le prochain token de manière que le résultat semble maximalement utile et approprié dans un contexte donné. Quand le contexte exige des données de contact—le modèle les génère. L'instruction « n'invente pas » entre en concurrence avec un comportement appris de milliards de paramètres ajustés pour l'utilité via RLHF. Dans cette compétition, le prompt perd presque toujours. Le désir du modèle d'être utile s'avère plus fort que toute interdiction verbale.
Cela signifie une conséquence concrète pour les produits : si votre service s'appuie sur un LLM pour fournir des données critiques—numéros de téléphone, adresses, noms de spécialistes, liens juridiques—vous construisez sur un fondement peu fiable. L'hallucination n'est pas une exception ; elle est intégrée à la nature du modèle. Plus vous le rendez « utile », plus fort est l'impulsion de donner une réponse même sans information fiable.
Qu'est-ce qui fonctionne à la place du prompting ? Le découplage architecturel. Les contacts sont stockés dans une base de données vérifiée, pas dans les poids du modèle. Le LLM reconnaît l'intention de l'utilisateur et appelle une fonction ou effectue une requête RAG : il récupère un numéro spécifique d'une ligne spécifique du tableau. Le modèle n'génère pas de chiffres—il les extrait. La différence est fondamentale.
Le function calling (tool use) résout la tâche directement. Vous décrivez un outil get_crisis_contact(region, type)—et avec l'intention appropriée, le modèle l'appelle au lieu d'inventer. La réponse provient de la base de données, non pas d'une distribution de probabilité de tokens.
Un schéma similaire est RAG avec un format de réponse strict : si aucun document n'est trouvé, le modèle doit l'indiquer explicitement plutôt que d'inventer. Une deuxième couche de protection est la validation de la sortie. Avant de transmettre à l'utilisateur une donnée de contact, elle doit être vérifiée : le numéro est-il sur une liste blanche vérifiée, le format est-il correct, est-il à jour ? Cela ne garantit pas l'infaillibilité—la base de données aussi doit être entretenue—mais c'est plusieurs ordres de grandeur plus fiable qu'une instruction dans un prompt.
Un troisième schéma est la séparation explicite des types de connaissances dans l'architecture. Il y a une connaissance que le modèle peut générer librement : ton, structure, empathie, interprétation de situations. Il y a une connaissance qu'il ne doit jamais générer : nombres spécifiques, adresses, recommandations médicales, données juridiquement significatives. L'architecture doit exclure physiquement ce dernier—pas demander au modèle de s'abstenir, mais ne pas lui en donner la possibilité d'emblée.
L'exemple avec la ligne d'écoute est significatif précisément parce que les enjeux sont élevés. Une personne en crise reçoit un mauvais numéro. Ce n'est pas un inconvénient—c'est un dommage potentiel. De tels scénarios en production sont beaucoup plus courants qu'on ne le reconnaît généralement : consultations juridiques, informations médicales, données financières, recommandations de spécialistes. Partout il y a un bot LLM qui veut sincèrement aider mais n'a pas accès à des informations vérifiées.
La conclusion est simple : le prompting n'est pas du contrôle—c'est un souhait. Si le comportement est critique pour la sécurité de l'utilisateur, sortez les données spécifiques du contrôle génératif du modèle. Donnez-lui des fonctions, des bases de données et des outils. Laissez-le comprendre le contexte et interpréter l'intention, mais pas inventer des faits. C'est cela, l'architecture—pas un ensemble de paroles magiques dans le system prompt.
Vous voulez cesser de lire sur l'IA et commencer à l'utiliser?
AI News est un fil d'actualité IA. Hamidun Academy vous apprend à utiliser l'IA dans votre travail.