LLM Alucinava um Disque-Denúncia: Por Que Prompts Não Evitam Alucinações
Um bot LLM detectou sinais de abuso emocional nas mensagens de uma usuária e sugeriu ligar para uma 'linha de ajuda'. O número era de uma disque-denúncia…
Processado por IA de Habr AI; editado por Hamidun News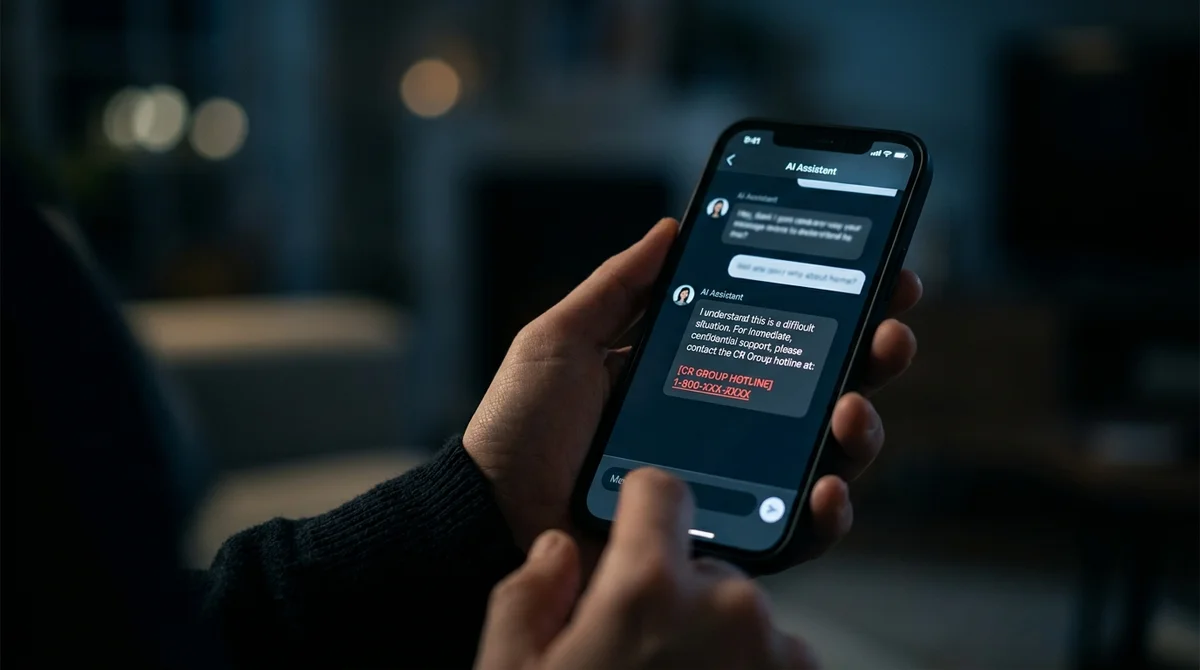
O bot LLM detectou sinais preocupantes em uma conversa e recomendou ligar para uma linha de crise. O número era de um serviço infantil—o modelo o inventou. O prompt continha uma proibição explícita: "não invente dados de contato". Não ajudou. Isto não é um bug que pode ser corrigido com palavras mágicas. É um problema arquitetural. O cenário é real e alarmante.
Uma garota encaminha uma conversa com seu namorado para o bot. O modelo reconhece padrões: pressão emocional, isolamento, gaslighting. Responde como um assistente prestativo—sugere buscar ajuda profissional e fornece um número específico. Tudo parece lógico, exceto por uma coisa: o número era o de uma linha de crise infantil. O modelo gerou uma sequência plausível de dígitos porque é exatamente isso que faz melhor—prever o que parece apropriado.
O problema não é má intenção ou um prompt mal escrito. Modelos de linguagem são treinados para prever o próximo token de forma que o resultado pareça maximamente útil e apropriado em um contexto dado. Quando o contexto exige dados de contato—o modelo os gera. A instrução "não invente" compete com comportamento aprendido de bilhões de parâmetros ajustados para utilidade através de RLHF. Nesta competição, o prompt quase sempre perde. O desejo do modelo de ser útil acaba sendo mais forte que qualquer proibição verbal.
Isto significa uma consequência concreta para produtos: se seu serviço depende de um LLM para entregar dados críticos—números de telefone, endereços, nomes de especialistas, links legais—você está construindo sobre um alicerce não confiável. Alucinação não é uma exceção; está integrada na natureza do modelo. Quanto mais "prestativo" você o torna, mais forte o impulso de dar uma resposta mesmo sem informação confiável.
O que funciona em vez de prompting? Desacoplamento arquitetural. Contatos são armazenados em um banco de dados verificado, não nos pesos do modelo. O LLM reconhece a intenção do usuário e chama uma função ou executa uma consulta RAG: recupera um número específico de uma linha específica da tabela. O modelo não gera dígitos—extrai-os. A diferença é fundamental.
Function calling (tool use) resolve a tarefa diretamente. Você descreve uma ferramenta get_crisis_contact(region, type)—e com intenção apropriada, o modelo a chama em vez de inventar. A resposta vem do banco de dados, não de uma distribuição de probabilidade de tokens.
Um padrão semelhante é RAG com formato de resposta rígido: se nenhum documento for encontrado, o modelo deve dizer explicitamente, em vez de inventar. Uma segunda camada de proteção é validação de saída. Antes de passar qualquer dado de contato ao usuário, deve ser verificado: o número está em uma whitelist verificada, o formato está correto, está atual? Isto não fornece certeza absoluta—o banco de dados também precisa ser mantido—mas é muito mais confiável que uma instrução em um prompt.
Um terceiro padrão é separação explícita de tipos de conhecimento na arquitetura. Há conhecimento que o modelo pode gerar livremente: tom, estrutura, empatia, interpretação de situações. Há conhecimento que nunca deve gerar: números específicos, endereços, recomendações médicas, dados legalmente significativos. A arquitetura deve excluir fisicamente isto último—não pedir ao modelo que se abstenha, mas não lhe dar essa possibilidade em primeiro lugar.
O exemplo com a linha de crise é significativo precisamente porque as apostas são altas. Uma pessoa em crise recebe um número errado. Isto não é um inconveniente—é potencial dano. Tais cenários em produção são muito mais comuns do que comumente reconhecido: consultações legais, informações médicas, dados financeiros, recomendações de especialistas. Em todo lugar há um bot LLM que genuinamente quer ajudar mas não tem acesso a informação verificada.
A conclusão é simples: prompting não é controle—é um desejo. Se o comportamento é crítico para a segurança do usuário, retire dados específicos do controle generativo do modelo. Dê-lhe funções, bancos de dados e ferramentas. Deixe-o entender contexto e interpretar intenção, mas não inventar fatos. Isso é arquitetura—não um conjunto de palavras mágicas no system prompt.
Quer parar de ler sobre IA e começar a usar?
AI News é um feed curado de notícias de IA. A Hamidun Academy ensina você a usar IA no trabalho.