A AI da OpenAI superou médicos no diagnóstico — mas cientistas pedem cautela
Uma LLM da OpenAI acertou o diagnóstico em 82% dos casos com base em histórias reais de atendimento de emergência — mais do que médicos (79% e 70%). Mas os pesq
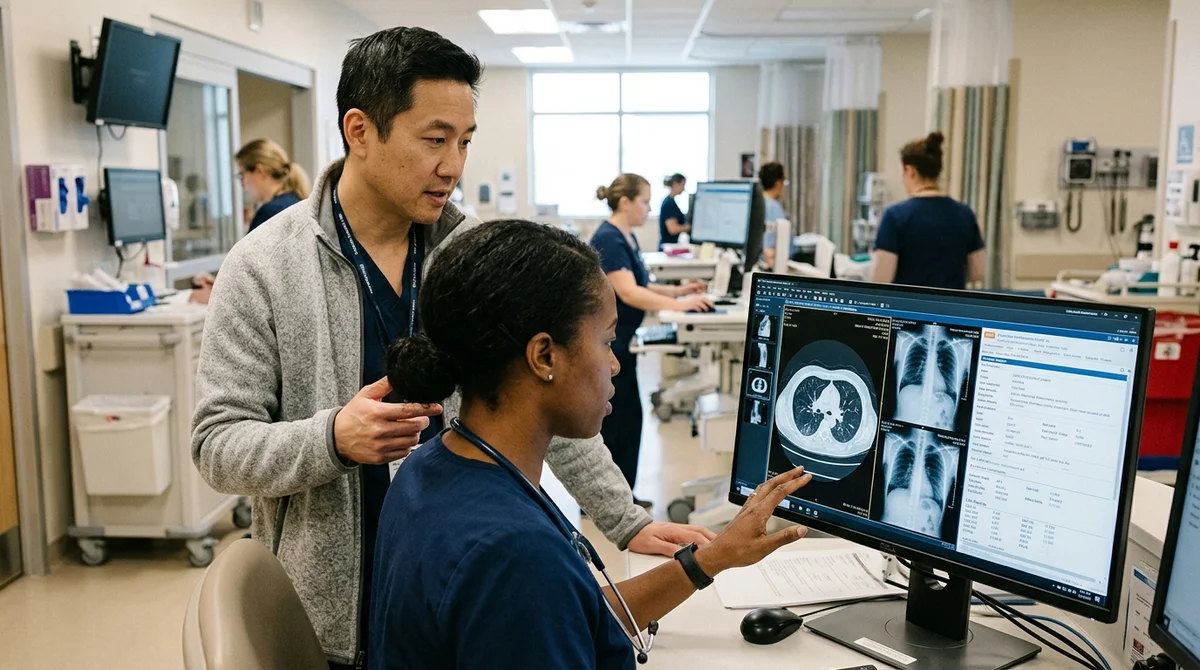
O modelo de linguagem do OpenAI superou os médicos em precisão diagnóstica em dados reais de atendimento de emergência pela primeira vez. A pesquisa foi publicada na revista Science em 30 de abril.
O Que o Estudo Mostrou
O modelo o1-preview do OpenAI analisou históricos médicos de 76 casos reais no departamento de emergência. Em diferentes estágios do tratamento—na admissão, após exame médico, após transferência para outro departamento—o modelo fez diagnósticos em paralelo com dois médicos. E acertou mais vezes: no estágio final, 82% de diagnósticos corretos versus 79% e 70% para os médicos. Interessantemente, tanto humanos quanto o modelo mostraram melhores resultados quando havia mais informações. Mas a IA manteve uma vantagem em todos os estágios, mesmo com dados incompletos.
- 82% de precisão diagnóstica versus 79% e 70% para médicos
- Testado em históricos reais de atendimento de emergência
- O modelo analisou conjuntos completos de detalhes
- Melhorou resultados com cada nova informação
Mas os Médicos São Cautelosos
Os autores do estudo apressam-se em esclarecer: a IA não substitui os médicos. "Não acho que nossos resultados significam que a IA deslocará os médicos", diz o coautor Arjun Manrai da Harvard Medical School. Seu colega Adam Rodman, instrutor de medicina em Boston, acrescenta: "Os resultados são incríveis, não me entendam mal, mas estou um pouco preocupado com como podem ser usados." O principal problema é que não há um padrão unificado para avaliar LLMs em tarefas médicas. Alguns pesquisadores consideram um sucesso se um modelo identifica 5 de 7 diagnósticos possíveis. Outros veem isso como um fracasso completo. O mesmo resultado é avaliado de forma diferente.
O Problema com a Confiabilidade dos Chatbots
Pesquisa paralela mostra que chatbots frequentemente mentem sobre questões médicas. Quase metade das respostas contém erros: fontes fabricadas, conselhos imprecisos, entrega confiante de falsidades. O modelo parece igualmente convincente, independentemente de estar correto ou não.
"Esses modelos são usados todos os dias, e há um certo risco que ninguém mede ou mitiga", —
Arya Rao, Harvard
Para um médico, a tarefa é mais complexa: quando o modelo fornece uma consulta, o médico precisa entender rapidamente se está correto ou é uma alucinação. Claro, um médico entenderá melhor qual informação importa. Mas detectar mentiras em uma resposta convincente é um desafio.
O Que Isso Significa
OpenAI já lançou ChatGPT para médicos e saúde. A tecnologia está se movendo mais rápido do que a medicina consegue regular e testar. São necessários testes clínicos reais e fluxos de trabalho claros, onde o médico usa a IA como assistente em consultas, não como a resposta final. A velocidade da inovação é importante, mas a responsabilidade é necessária ainda mais.