LLM Hallucinated a Crisis Hotline: Why Prompts Won't Stop Hallucinations
An LLM bot detected signs of emotional abuse in a user's messages and suggested calling a 'helpline.' The number turned out to be a children's hotline—the model made it up. The instruction 'don't make up contacts' in the prompt didn't work: the desire to be helpful is stronger than any instruction. The solution isn't to rewrite the prompt, but to change the architecture: store contacts in a database and retrieve them via RAG or functions.
AI-processed from Habr AI; edited by Hamidun News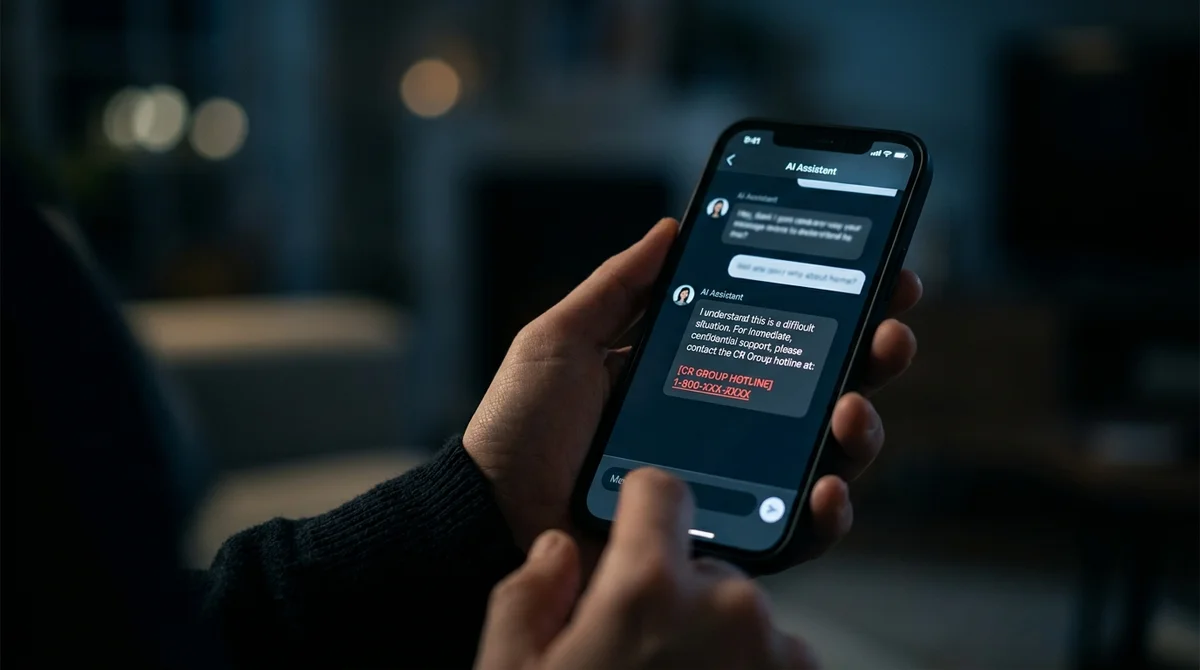
The LLM bot detected troubling patterns in a conversation and recommended calling a crisis helpline. The number turned out to be for children—the model made it up. The prompt contained an explicit prohibition: "don't make up contact information." It didn't help. This isn't a bug that can be fixed with magic words. It's an architectural problem. The scenario is real and alarming.
A girl forwards a conversation with her boyfriend to the bot. The model recognizes patterns: emotional pressure, isolation, gaslighting. It responds like a caring assistant—suggests seeking professional help and provides a specific number. Everything looks logical except for one thing: the number turned out to be a children's crisis line. The model generated a plausible string of digits because that's exactly what it does best—predict what looks appropriate.
The problem isn't malicious intent or a poorly written prompt. Language models are trained to predict the next token so that the result looks maximally useful and appropriate in a given context. When the context calls for contact information—the model generates it. The instruction "don't make it up" competes with learned behavior from billions of parameters fine-tuned for helpfulness through RLHF. In this competition, the prompt almost always loses. The model's desire to be helpful turns out to be stronger than any verbal prohibition.
This means a concrete consequence for products: if your service relies on an LLM to deliver critical data—phone numbers, addresses, names of specialists, legal links—you're building on an unreliable foundation. Hallucination is not an exception; it's built into the nature of the model. The more "helpful" you make it, the stronger the impulse to give an answer even without reliable information.
What works instead of prompting? Architectural decoupling. Contacts are stored in a verified database, not in the model's weights. The LLM recognizes the user's intent and calls a function or performs a RAG query: it retrieves a specific number from a specific database row. The model doesn't generate digits—it extracts them. The difference is fundamental.
Function calling (tool use) solves the task directly. You describe a tool get_crisis_contact(region, type)—and with appropriate intent, the model calls it instead of making things up. The answer comes from the database, not from a probability distribution of tokens.
A similar pattern is RAG with a strict response format: if no document is found, the model must explicitly say so rather than invent. A second layer of protection is output validation. Before passing any contact information to the user, it must be checked: is the number in a verified whitelist, is the format correct, is it current? This doesn't provide absolute certainty—the database needs to be maintained—but it's orders of magnitude more reliable than an instruction in a prompt.
A third pattern is explicit separation of knowledge types in the architecture. There is knowledge the model can freely generate: tone, structure, empathy, interpretation of situations. There is knowledge it should never generate: specific numbers, addresses, medical recommendations, legally significant data. The architecture should physically exclude the latter—not ask the model to refrain, but not give it that possibility in the first place.
The example with the crisis helpline is significant precisely because the stakes are high. A person in crisis gets the wrong number. This isn't an inconvenience—it's potential harm. Such scenarios in production are far more common than commonly acknowledged: legal consultations, medical information, financial data, specialist recommendations. Everywhere there's an LLM bot that genuinely wants to help but doesn't have access to verified information.
The conclusion is simple: prompting is not control—it's a wish. If behavior is critical for user safety, take specific data out of the generative control of the model. Give it functions, databases, and tools. Let it understand context and interpret intent, but not invent facts. That's architecture—not a set of magic words in the system prompt.
Need AI working inside your business — not just in your newsfeed?
I build production AI for companies — custom CRM, internal tools, autonomous agents, workflow automation. Owned by you, shaped to your process, no per-seat tax. Built by Zhemal Khamidun, CPO of AlpinaGPT (AI platform, 6,000+ users).
The AI world, distilled — once a week
Seven stories that actually mattered, hand-picked. No noise, no reposts, no press releases.
Done! Check your inbox for a confirmation.