Anthropic and Claude Opus 4.7: Actual Token Consumption Exceeded Claimed Figures
Claude Opus 4.7's tokenizer proved far more token-hungry than Anthropic advertised. Two real-world benchmarks showed a 1.47x increase on technical…
AI-processed from Habr AI; edited by Hamidun News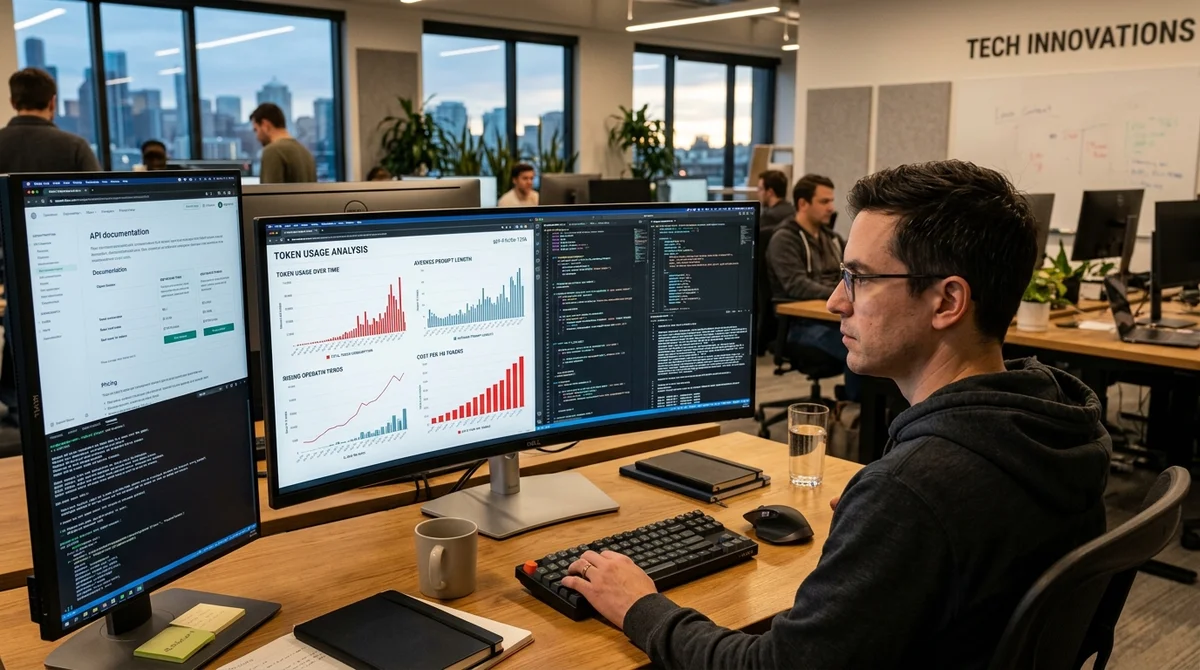
The new Claude Opus 4.7 tokenizer may significantly increase the cost of using the model: in real-world tests, consumption came out closer to 45–47%, rather than the 0–35% claimed in Anthropic's migration guide. For teams working with long prompts, large system instructions, and cacheable prefixes, this is not a cosmetic difference but a direct hit to quotas, speed, and the cost of each session.
The reason for this analysis was the discrepancy between promises and practice. In Anthropic's documentation, it states that the new tokenizer uses approximately 1.0–1.
35 times more tokens compared to the version for Opus 4.6. The author decided to check this not on abstract examples, but on materials that actually resemble developers' real workload.
In the first measurement, he ran technical documentation through the tokenizer and got growth up to 1.47x. In the second, he took a real CLAUDE.
md file—a large instructional context—and saw almost the same result: 1.45x. The difference from the upper bound in the guide is too large to consider it normal measurement noise.
The problem is not the fact of token growth itself: sometimes a heavier tokenizer actually does give benefits in quality, stability, or support for complex texts. The question is that Anthropic doesn't change prices and quotas in response. If the same text now takes up more tokens, then the user hits context limits faster, encounters rate limits sooner, and spends more budget per iteration.
This is particularly painful for scenarios with long system prompts, sets of rules, example responses, chunks of documentation, and cacheable prefixes that are sent again and again. On paper the rate is the same, but the actual usable capacity is lower. That's why the author went further than simple counting and tried to understand what exactly the model gets in return.
Based on the description of the experiment, the claimed advantages of the new tokenizer and its behavior on practical tasks were tested. The key conclusion is that no miraculous compensation occurred: at least in the tested scenarios, the increase in consumption was very noticeable, and the benefit didn't look nearly as obvious and systematic. In other words, from the perspective of someone who pays for tokens or lives within subscription quotas, the trade-off looks unfavorable to the user.
This doesn't necessarily mean Opus 4.7 is worse as a model, but it does mean its economics became less comfortable. For the market, this is an important signal.
The tokenizer is rarely discussed outside a narrow circle of engineers, although it is precisely what determines how much real text fits in the context window and how much each operation costs on top of the API. A 5–10% difference is often tolerable and can be lost in the background of normal request variability. But a jump of approximately 45% is no longer a technical trifle but a factor that affects agent architecture, the length of system instructions, caching strategy, and even the unit economics of a product.
If a team has a pipeline where the same large prefix participates in hundreds of calls, the extra tokens start eating money and throughput very quickly. The practical conclusion is simple: migration to Claude Opus 4.7 should be evaluated not by the marketing formulation in the migration guide, but by your own real text corpora.
It's worth separately running system prompts, instruction files, documentation, agent task templates, and everything that often lands in context. If measurements show growth close to 1.45x, the team may have to trim prompts, move some logic out of context, reconsider caching, or even delay migration until clearer benefits emerge.
The main lesson here is that model quality cannot be evaluated solely by demos and benchmarks: sometimes what matters most is not the intelligence of the response, but the cost of each extra token.
Want to stop reading about AI and start using it?
AI News is a curated feed of AI/tech news. Hamidun Academy teaches you to use AI systematically in your work.