LLM اختلقت خط مساعدة: لماذا الرموز لا توقف الهلوسات
اكتشف روبوت LLM علامات الإساءة العاطفية في رسائل المستخدمة واقترح عليها الاتصال بـ 'خط مساعدة'. الرقم كان خط مساعدة للأطفال—اختلقه النموذج. فشلت تعليمات 'لا…
معالج بواسطة الذكاء الاصطناعي من Habr AI؛ بتحرير Hamidun News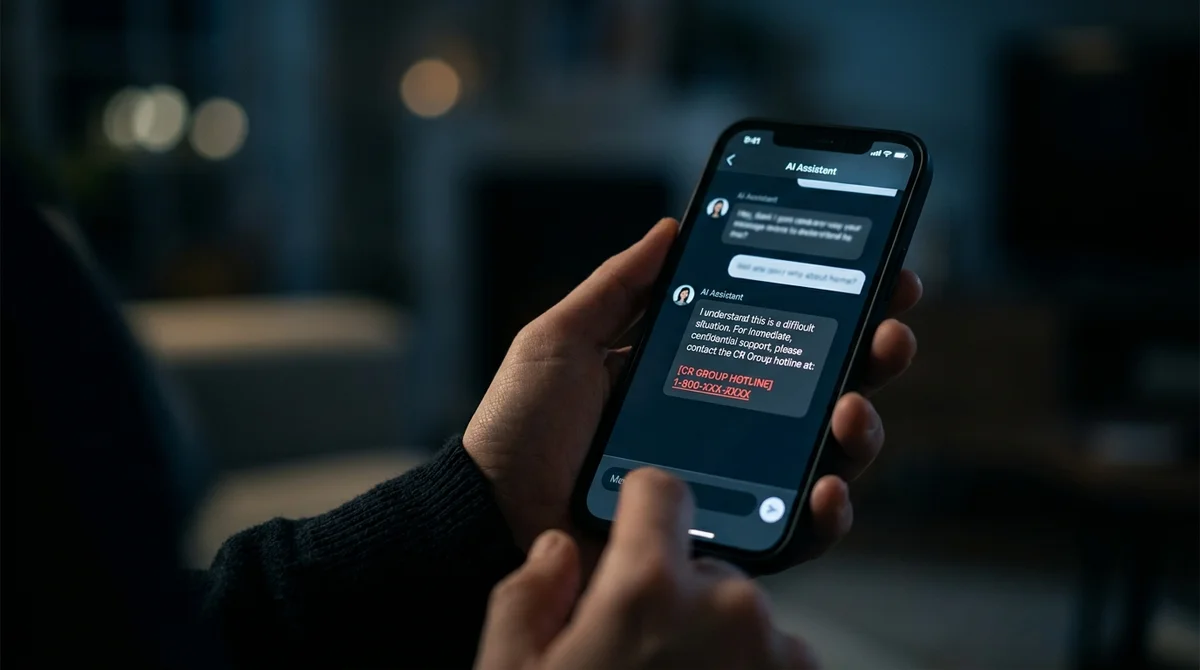
اكتشف برنامج LLM الآلي إشارات مقلقة في محادثة وأوصى بالاتصال بخط الأزمات. تبين أن الرقم كان خاصاً بخدمة للأطفال—اختلقه النموذج. كان في prompt حظر صريح: "لا تختلق بيانات الاتصال". لم يساعد ذلك. هذا ليس خللاً يمكن إصلاحه بكلمات سحرية. إنها مشكلة معمارية. السيناريو واقعي ومثير للقلق.
تحول فتاة محادثة مع صديقها إلى البرنامج الآلي. يتعرف النموذج على أنماط: الضغط العاطفي، العزلة، التلاعب النفسي. يستجيب كمساعد متعاطف—يقترح البحث عن المساعدة المهنية ويقدم رقماً محدداً. يبدو كل شيء منطقياً باستثناء شيء واحد: الرقم تبين أنه كان لخط أزمات للأطفال. ولدّ النموذج سلسلة معقولة من الأرقام لأن هذا بالضبط ما يفعله بشكل أفضل—التنبؤ بما يبدو مناسباً.
المشكلة ليست نية خبيثة وليست prompt مكتوباً بسوء. يتم تدريب نماذج اللغة على التنبؤ بالرمز التالي بطريقة تجعل النتيجة مفيدة ومناسبة قدر الإمكان في السياق المعطى. عندما يتطلب السياق بيانات اتصال—ينتجها النموذج. تتنافس التعليمات "لا تختلقها" مع السلوك المتعلم من مليارات المعاملات المضبوطة للفائدة عبر RLHF. في هذا التنافس، يخسر prompt دائماً تقريباً. يثبت رغبة النموذج في أن يكون مفيداً أقوى من أي حظر لفظي.
هذا يعني نتيجة ملموسة للمنتجات: إذا كان خدمتك تعتمد على LLM لتسليم بيانات حرجة—أرقام هاتفية، عناوين، أسماء متخصصين، روابط قانونية—فأنت تبني على أساس غير موثوق. الهلوسة ليست استثناء؛ إنها مدمجة في طبيعة النموذج. كلما زادت "عطفك" على النموذج، زاد الدافع لإعطاء إجابة حتى بدون معلومات موثوقة.
ما الذي يعمل بدلاً من prompting؟ الفصل المعماري. يتم تخزين جهات الاتصال في قاعدة بيانات موثقة، وليس في أوزان النموذج. يتعرف LLM على قصد المستخدم ويستدعي دالة أو يجري استعلام RAG: يسترجع رقماً محدداً من صف محدد في الجدول. النموذج لا يولد الأرقام—يستخرجها. الفرق أساسي.
يحل function calling (tool use) المهمة بشكل مباشر. تصف أداة get_crisis_contact(region, type)—وبالنية المناسبة، يستدعيها النموذج بدلاً من الاختلاق. تأتي الإجابة من قاعدة البيانات، وليس من توزيع احتمالي للرموز.
نمط مشابه هو RAG بصيغة إجابة صارمة: إذا لم يتم العثور على مستند، يجب على النموذج أن يقول ذلك صراحةً بدلاً من الاختلاق. الطبقة الثانية من الحماية هي التحقق من صحة الإخراج. قبل تمرير أي بيانات اتصال للمستخدم، يجب فحصها: هل الرقم في قائمة بيضاء موثقة، هل الصيغة صحيحة، هل هو حالياً؟ هذا لا يوفر ضمان مطلق—يجب أيضاً صيانة قاعدة البيانات—لكنه موثوق بأوامر من حيث الحجم أكثر من تعليمات في prompt.
النمط الثالث هو الفصل الصريح بين أنواع المعرفة في المعمارية. هناك معرفة يمكن للنموذج أن يولدها بحرية: النبرة، البنية، التعاطف، تفسير الحالات. وهناك معرفة لا يجب أن يولدها أبداً: أرقام محددة، عناوين، توصيات طبية، بيانات ذات أهمية قانونية. يجب أن تستبعد المعمارية فعلياً الأخير—لا تطلب من النموذج الامتناع، بل لا تعطه هذا الاحتمال من الأساس.
مثال خط الأزمات مهم بالضبط لأن الرهانات عالية. يتلقى الشخص في أزمة رقماً خاطئاً. هذا ليس إزعاجاً—إنه ضرر محتمل. هذه السيناريوهات في الإنتاج أكثر شيوعاً بكثير مما يُعترف به عادةً: استشارات قانونية، معلومات طبية، بيانات مالية، توصيات متخصصين. في كل مكان برنامج آلي LLM يريد بصدق المساعدة لكن ليس لديه إمكانية الوصول إلى معلومات موثقة.
الخلاصة بسيطة: prompting ليس التحكم—بل رغبة. إذا كان السلوك حرجاً لسلامة المستخدم، أخرج البيانات المحددة من السيطرة التوليدية للنموذج. أعطه الدوال وقواعد البيانات والأدوات. دعه يفهم السياق ويفسر النية، لكن لا يختلق الحقائق. هذه هي المعمارية—وليست مجموعة من الكلمات السحرية في system prompt.
هل تريد التوقف عن قراءة الذكاء الاصطناعي والبدء باستخدامه؟
AI News هو موجز منسق لأخبار الذكاء الاصطناعي. تعلمك Hamidun Academy استخدام الذكاء الاصطناعي في عملك.