AI OpenAI превзошла врачей в диагностике — но учёные осторожничают
OpenAI LLM угадала диагноз в 82% случаев из реальных историй скорой помощи — больше, чем врачи (79% и 70%). Но исследователи предупреждают: нет единого…
AI-обработка оригинала IEEE Spectrum AI; редакция Hamidun News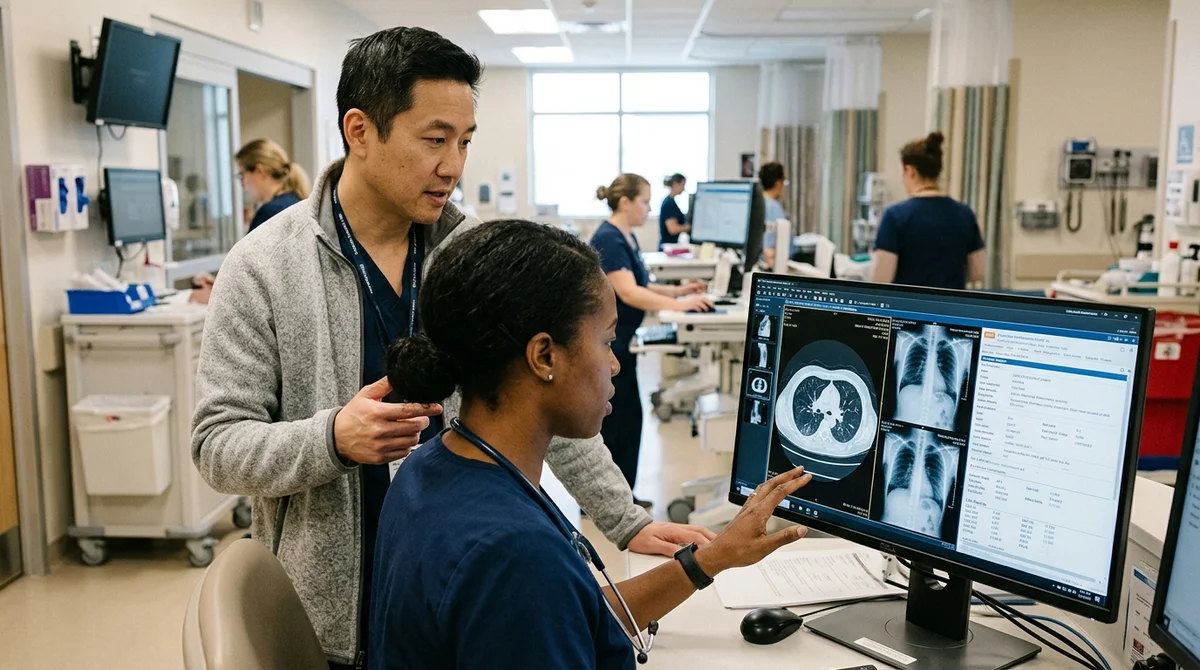
Модель языка OpenAI впервые превзошла врачей по точности диагностики на реальных данных скорой помощи. Исследование опубликовано в журнале Science 30 апреля.
Что показало исследование
Модель o1-preview от OpenAI проанализировала истории болезни из 76 реальных случаев в отделении скорой помощи. На разных этапах лечения — при поступлении, после осмотра врача, после перевода в другое отделение — модель выставляла диагноз параллельно двум медикам. И она угадывала чаще: в финальной точке 82% верных диагнозов против 79% и 70% у врачей.
Интересно, что и люди, и модель показывали лучшие результаты, когда было больше информации. Но AI держала преимущество на всех стадиях, даже с неполными данными. 82% точности диагностики против 79% и 70% у врачей Протестировано на реальных истории скорой помощи Модель анализировала полные наборы деталей Улучшала результаты с каждой новой информацией ## Но медики осторожничают Авторы исследования сами спешат уточнить: AI не заменяет докторов.
«Я не думаю, что наши результаты означают, что AI вытеснит врачей», — говорит соавтор Арджун Манрай из Гарвардской медицинской школы. Его коллега Адам Родман, преподаватель медицины в Бостоне, добавляет: «Результаты крутые, не поймите неправильно, но я слегка беспокоюсь, как их могут использовать». Главная проблема — нет единого стандарта, как вообще оценивать LLM на медицинских задачах.
Одни исследователи считают за успех, если модель назвала 5 из 7 возможных диагнозов. Другие это воспринимают как полный провал. Один и тот же результат оценивают по-разному.
Проблема с надёжностью чатботов
Параллельные исследования показывают, что чатботы часто врут при медицинских вопросах. Почти половина ответов содержит ошибки: выдуманные источники, неточные советы, уверенная подача неправды. Модель выглядит одинаково убедительно, правильна она или нет.
«Эти модели используют каждый день, и есть определённый риск, который никто не измеряет и не снижает», —
Арья Рао, Harvard Для врача задача сложнее: когда модель даёт консультацию, доктору нужно быстро понять, правильно это или галлюцинация. Медик, конечно, лучше поймёт, какая информация важна. Но детектировать ложь в убедительном ответе — это вызов.
Что это значит OpenAI уже запустила ChatGPT для врачей и для здравоохранения.
Технология движется быстрее, чем медицина успевает регулировать и тестировать. Нужны реальные клинические испытания и чёткие рабочие процессы, где врач использует AI как помощника на совещаниях, а не как окончательный ответ. Скорость инноваций важна, но ответственность нужна больше.
Хотите не читать про ИИ, а внедрить его?
«AI News» — это полезные новости из мира ИИ. Системно научиться работать с нейросетями и применять их в работе — в Hamidun Academy.
Главное из мира ИИ — раз в неделю
7 ключевых событий недели, отобранных вручную. Без шума, репостов и пресс-релизов.
Готово! Проверьте почту — мы отправили подтверждение.