Anthropic y Claude Opus 4.7: el consumo real de tokens superó lo anunciado
El tokenizador de Claude Opus 4.7 resultó mucho más voraz de lo que Anthropic había anunciado. En dos pruebas prácticas, el aumento fue de 1.47x en…
Procesado por IA desde Habr AI; editado por Hamidun News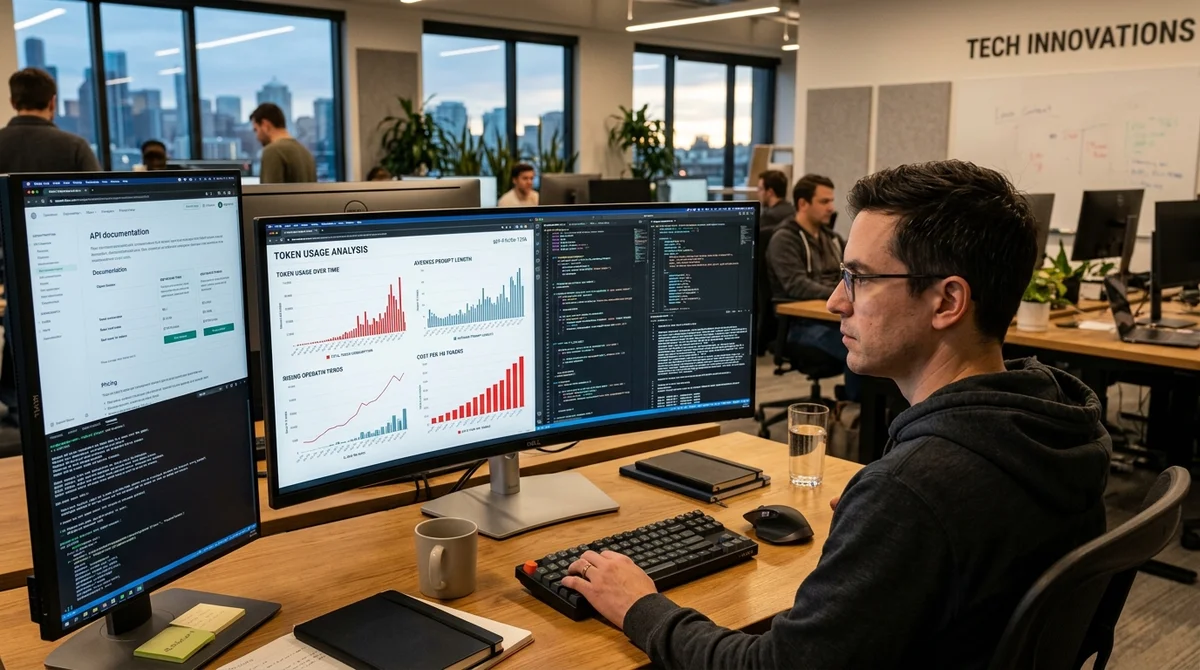
El nuevo tokenizador de Claude Opus 4.7 puede aumentar significativamente el costo de usar el modelo: en pruebas reales, el consumo resultó ser más cercano al 45–47%, en lugar del 0–35% afirmado en la guía de migración de Anthropic. Para equipos que trabajan con prompts largos, instrucciones de sistema amplias y prefijos cacheables, esta no es una diferencia cosmética sino un golpe directo a las cuotas, velocidad y costo de cada sesión.
El motivo de este análisis fue la discrepancia entre promesas y práctica. En la documentación de Anthropic se indica que el nuevo tokenizador utiliza aproximadamente 1,0–1,35 veces más tokens comparado con la versión para Opus 4.6.
El autor decidió verificar esto no en ejemplos abstractos, sino en materiales que realmente se asemejan a la carga de trabajo real de los desarrolladores. En la primera medición, ejecutó documentación técnica a través del tokenizador y obtuvo un crecimiento de hasta 1,47x. En la segunda, tomó un archivo CLAUDE.
md real—un contexto instructivo grande—y vio casi el mismo resultado: 1,45x. La diferencia respecto al límite superior de la guía es demasiado grande para considerarla ruido de medición normal. El problema no es el hecho del crecimiento de tokens en sí: a veces un tokenizador más pesado realmente ofrece beneficios en calidad, estabilidad o soporte para textos complejos.
La cuestión es que Anthropic no cambia los precios y cuotas en respuesta. Si el mismo texto ahora ocupa más tokens, entonces el usuario alcanza límites de contexto más rápido, encuentra límites de velocidad antes y gasta más presupuesto por iteración. Esto es particularmente doloroso para escenarios con prompts de sistema largos, conjuntos de reglas, respuestas de ejemplo, fragmentos de documentación y prefijos cacheables que se envían una y otra vez.
En el papel la tarifa es la misma, pero la capacidad realmente útil es menor. Por eso el autor fue más allá de simplemente contar e intentó entender qué exactamente recibe el modelo a cambio. Según la descripción del experimento, se probaron las ventajas afirmadas del nuevo tokenizador y su comportamiento en tareas prácticas.
La conclusión clave es que no ocurrió ninguna compensación milagrosa: al menos en los escenarios probados, el aumento en el consumo fue muy notable, y el beneficio no parecía ni remotamente tan obvio y sistemático. En otras palabras, desde la perspectiva de alguien que paga por tokens o vive dentro de cuotas de suscripción, el intercambio se ve desfavorable para el usuario. Esto no necesariamente significa que Opus 4.
7 sea peor como modelo, pero sí significa que su economía se volvió menos confortable. Para el mercado, esta es una señal importante. El tokenizador rara vez se discute fuera de un círculo estrecho de ingenieros, aunque es precisamente lo que determina cuánto texto real cabe en la ventana de contexto y cuánto cuesta cada operación además de la API.
Una diferencia del 5–10% a menudo es tolerable y puede perderse en el contexto de la variabilidad normal de solicitudes. Pero un salto de aproximadamente 45% ya no es una pequeñez técnica sino un factor que afecta la arquitectura de agentes, la longitud de instrucciones de sistema, la estrategia de caching e incluso la economía unitaria de un producto. Si un equipo tiene un pipeline donde el mismo prefijo grande participa en cientos de llamadas, los tokens extra comienzan a consumir dinero y throughput muy rápidamente.
La conclusión práctica es simple: la migración a Claude Opus 4.7 debe evaluarse no por la formulación de marketing en la guía de migración, sino por sus propios corpus de texto real. Vale la pena ejecutar por separado prompts de sistema, archivos de instrucciones, documentación, plantillas de tareas de agente, y todo lo que frecuentemente entra en contexto.
Si las mediciones muestran crecimiento cercano a 1,45x, el equipo podría tener que recortar prompts, mover parte de la lógica fuera del contexto, reconsiderar caching, o incluso aplazar la migración hasta que beneficios más claros emerjan. La lección principal aquí es que la calidad del modelo no puede evaluarse solo por demos y benchmarks: a veces lo que realmente importa no es la inteligencia de la respuesta, sino el costo de cada token extra.
¿Quieres dejar de leer sobre IA y empezar a usarla?
AI News es un feed curado de noticias de IA. Hamidun Academy te enseña a usar la IA en tu trabajo.