Por qué LoRA falla en producción y cómo RS-LoRA salva el ajuste fino de modelos
LoRA funciona bien cuando los modelos necesitan cambiar tono, formato o personalidad, pero funciona peor cuando se necesita añadir nuevos hechos a ella. El…
Procesado por IA desde MarkTechPost; editado por Hamidun News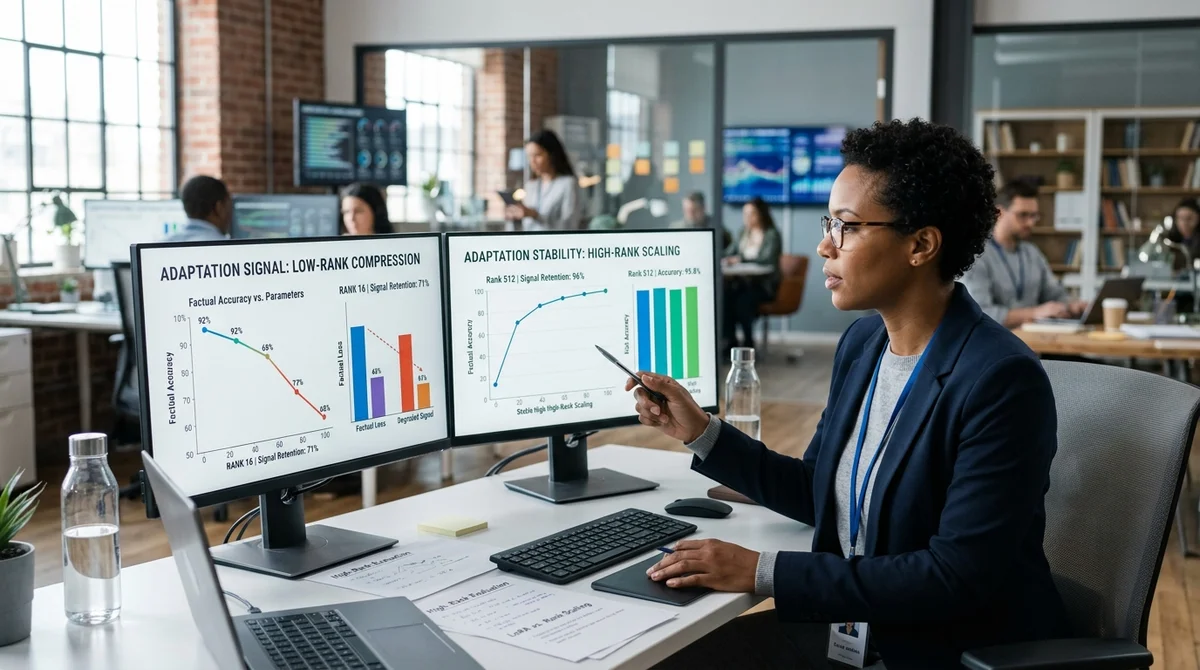
LoRA se ha convertido hace tiempo en el estándar para el fine-tuning barato de grandes modelos, pero en producción reposa sobre una suposición oculta: que todas las actualizaciones de pesos se estructuran de la misma manera. En la práctica, esto no es así — los cambios responsables del estilo son efectivamente compactos, mientras que las actualizaciones que añaden nuevos hechos y experiencia de dominio se distribuyen entre muchas dimensiones, y es precisamente aquí donde el LoRA estándar comienza a perder datos. La popularidad de LoRA es comprensible: el método permite fine-tuning de un modelo sin recalcular todos los parámetros, utilizando pequeñas matrices de bajo rango.
Esto funciona muy bien cuando necesitas cambiar tono, formato de respuesta, carácter o hábitos del habla del asistente. El artículo lo demuestra en una matriz de pesos simplificada de 64×64: en actualizaciones de estilo, varios valores singulares dominan fuertemente, por lo que una aproximación de rango 4 u 8 preserva la señal casi completamente. En su simulación, incluso en rango 4, logran cubrir más del 99% de la variación útil.
Por lo tanto, un chatbot aprende fácilmente un nuevo estilo de comunicación, plantilla de respuesta o manera deseada sin reentrenamiento pesado de todo el modelo. Los problemas comienzan donde necesitas enseñar no forma, sino contenido: hechos médicos, catálogos de productos, regulaciones internas, estadísticas o reglas de la industria. Tales actualizaciones se comportan como alto rango: la información se dispersa entre muchas direcciones en lugar de concentrarse en unos pocos componentes dominantes.
En el experimento del artículo, rango 8 retiene solo alrededor del 28% de la señal real. De ahí el efecto familiar en producción: el modelo suena confiante, usa terminología correcta y estructura adecuada de respuesta, pero confunde números, pierde detalles o da conclusiones incompletas. Para asistentes corporativos, análisis, soporte y escenarios dependientes del conocimiento, esto ya no es un error cosmético sino un riesgo de calidad.
La diferencia clave es claramente visible en el espectro de valores singulares. Las tareas de estilo tienen un codo obvio: después de algunos componentes, dimensiones adicionales aportan casi nada. Con hechos — una cola larga, donde cada componente sucesivo añade parte del conocimiento útil.
Cuando LoRA corta drásticamente tal actualización a rango bajo, corta precisamente esa cola. Externamente, el sistema aún puede parecer mejorado porque formato, tono y estructura se volvieron más limpios, pero la precisión real crece notablemente menos de lo que parece en pruebas superficiales. Esto explica por qué respuestas hermosas en demostraciones y buen estilo no garantizan comportamiento confiable en datos de producción.
La reacción lógica del ingeniero es simplemente aumentar el rango. Pero el LoRA estándar tiene un segundo problema oculto: escalado de alpha/r. Cuanto mayor sea el rango, más fuertemente se comprime el coeficiente y más débil se vuelve la señal de entrenamiento.
En el ejemplo con alpha = 16, la escala cae de 16 en rango 1 a 0,25 en rango 64. Obtienes una paradoja: añades capacidad al modelo para que pueda representar una actualización más compleja, pero simultáneamente reduces el impacto real de esa actualización en los pesos. El optimizador tiene que compensar con pasos más agresivos, lo que hace que el entrenamiento converja mal o se vuelva inestable.
Por eso el consejo de aumentar el rango en producción frecuentemente no resuelve el problema e incluso a veces solo lo enmascara. RS-LoRA ofrece una corrección mínima pero importante: usar alpha/√r en lugar de alpha/r. Formalmente esto es casi solo reemplazar un símbolo, pero en la práctica el efecto es significativo.
En rango 64, la escala permanece en 2,0 en lugar de 0,25, por lo que la adaptación de alto rango preserva magnitud significativa y no mata la señal. El artículo lo demuestra sin bucles de entrenamiento pesados ni frameworks — solo mediante NumPy, SVD y comparación de errores de reconstrucción. Por eso, el argumento se ve especialmente claro: las tareas de estilo de bajo rango siguen siendo bien resueltas por LoRA estándar, mientras que las tareas de adición de conocimiento requieren o bien RS-LoRA o una estrategia de adaptación fundamentalmente diferente desde el inicio.
La conclusión para equipos que despliegan LLMs fine-tuned en producción es bastante directa: la configuración del adaptador debe elegirse no solo por presupuesto y velocidad, sino también por el tipo de actualización. Si estás cambiando tono, carácter o formato de respuesta, el LoRA de bajo rango estándar es generalmente suficiente. Si estás implementando nuevos hechos, datos de referencia, reglas o experiencia de dominio, el rango bajo puede crear una ilusión de entrenamiento exitoso mientras silenciosamente pierde una parte sustancial de la información.
En tales casos, RS-LoRA no parece una optimización sutil, sino un requisito para la confiabilidad del modelo en operación real.
¿Quieres dejar de leer sobre IA y empezar a usarla?
AI News es un feed curado de noticias de IA. Hamidun Academy te enseña a usar la IA en tu trabajo.