Why LoRA Breaks in Production and How RS-LoRA Saves Model Fine-tuning
LoRA works well when models need to change tone, format, or persona, but performs worse when adding new facts to it. The problem is that low rank cuts off…
AI-processed from MarkTechPost; edited by Hamidun News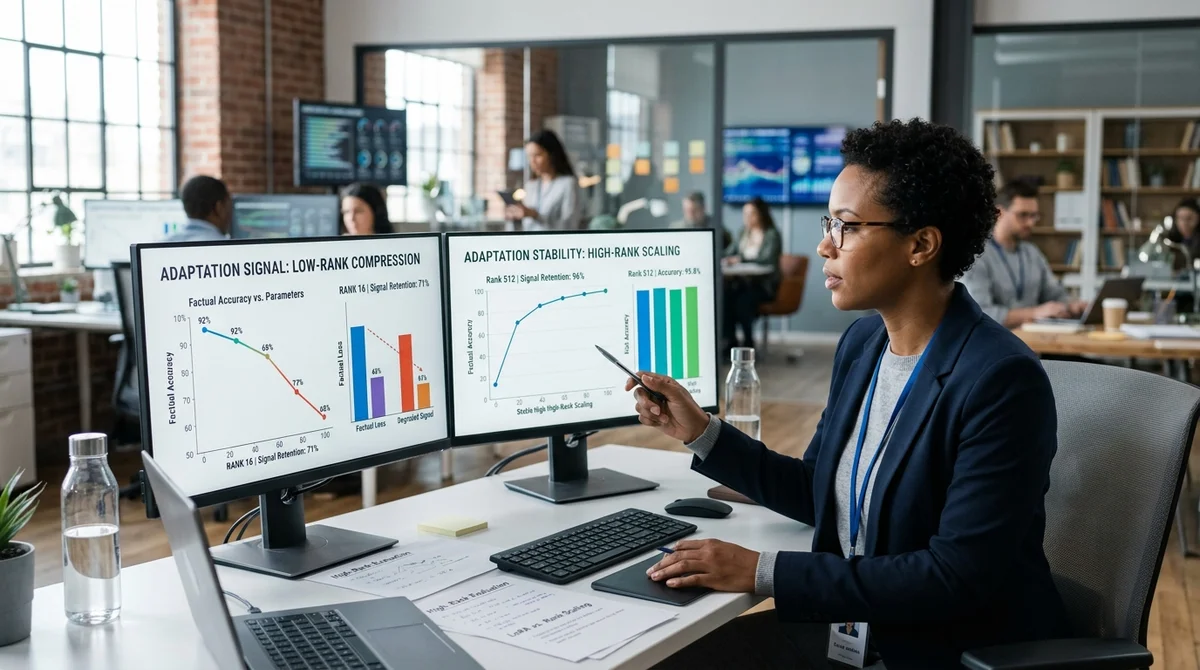
LoRA has long been the standard for cheap fine-tuning of large models, but in production it relies on a hidden assumption: that all weight updates are structured the same way. In practice, this is not the case — changes responsible for style are indeed compact, while updates that add new facts and domain expertise are distributed across many dimensions, and this is precisely where standard LoRA begins to lose data. The popularity of LoRA is understandable: the method allows fine-tuning a model without recalculating all parameters, using small low-rank matrices.
This works great when you need to change tone, answer format, character, or the assistant's speech habits. The article demonstrates this on a simplified weight matrix of 64×64: in style updates, several singular values dominate sharply, so rank-4 or rank-8 approximation preserves the signal almost completely. In their simulation, even at rank 4, they manage to cover more than 99% of useful variation.
Therefore, a chatbot easily learns new communication style, answer template, or desired manner without heavy retraining of the entire model. Problems begin where you need to teach not form, but content: medical facts, product catalogs, internal regulations, statistics, or industry rules. Such updates behave like high-rank: information is smeared across many directions rather than concentrated in a few dominant components.
In the article's experiment, rank 8 retains only about 28% of the actual signal. Hence the familiar production effect: the model sounds confident, uses correct terminology and proper answer structure, but confuses numbers, misses details, or gives incomplete conclusions. For corporate assistants, analytics, support, and knowledge-dependent scenarios, this is no longer a cosmetic error but a quality risk.
The key difference is clearly visible in the spectrum of singular values. Style tasks have an obvious elbow: after a few components, additional dimensions contribute almost nothing. With facts — a long tail, where each successive component adds part of useful knowledge.
When LoRA sharply cuts such an update to a low rank, it cuts off precisely this tail. Externally, the system may still appear improved because format, tone, and structure became neater, but actual accuracy grows noticeably less than it seems from surface tests. This explains why beautiful-looking demo answers and good style do not guarantee reliable behavior on production data.
The logical engineer reaction is to simply raise the rank. But standard LoRA has a second hidden problem: alpha/r scaling. The higher the rank, the stronger the coefficient is compressed and the weaker the training signal becomes.
In the example with alpha = 16, the scale drops from 16 at rank 1 to 0.25 at rank 64. You get a paradox: you add capacity to the model so it can represent a more complex update, but simultaneously reduce the actual impact of that update on the weights.
The optimizer has to compensate with more aggressive steps, which causes training to either converge poorly or become unstable. That is why the advice to raise the rank in production often does not solve the problem and sometimes only masks it. RS-LoRA offers a minimal but important fix: use alpha/√r instead of alpha/r.
Formally this is almost just replacing one symbol, but in practice the effect is significant. At rank 64, the scale remains 2.0 instead of 0.
25, so high-rank adaptation preserves meaningful magnitude and does not kill the signal. The article demonstrates this without heavy training loops and frameworks — only through NumPy, SVD, and comparison of reconstruction errors. Because of this, the argument looks especially clear: low-rank style tasks are still well-solved by standard LoRA, while knowledge-addition tasks require either RS-LoRA or a fundamentally different adaptation strategy from the start.
The conclusion for teams rolling out fine-tuned LLMs to production is quite direct: adapter configuration must be chosen not only by budget and speed, but also by the type of update. If you are changing tone, character, or answer format, standard low-rank LoRA is usually sufficient. If you are deploying new facts, reference data, rules, or domain expertise, low rank can create an illusion of successful training while quietly losing a substantial part of the information.
In such cases, RS-LoRA looks not like a subtle optimization, but like a requirement for model reliability in actual operation.
Want to stop reading about AI and start using it?
AI News is a curated feed of AI/tech news. Hamidun Academy teaches you to use AI systematically in your work.